Choreonoidを使用していて何か処理が重くて原因を探りたい時に、プロファイリングをとることが考えられます。
そのためのプロファイラツールはいろいろとありますが、Google Performance Tools に含まれるプロファイラが比較的簡単に使えることが分かったので紹介します。こちらのツールのGithubリポジトリは以下になります。
以下のコマンドでインストールできます。
sudo apt install google-perftools libgoogle-perftools-dev kcachegrind
利用にあたってはプロファイリングをしたいプログラムprofiler (libprofile.so)というライブラリをリンクしておく必要があります。
また、プロファイリング対象のプログラムで
#include <gperftools/profiler.h>
として、開始の際に
ProfilerStart("choreonoid.prof");
などとし、終了時に
ProfilerStop();
とします。
それか、プロセス全体の開始と終了にプロファイリングを連動させるのなら、このようにコードを埋め込まなくても、環境変数CPUPROFILEに記録ファイルのパスを設定してプロセスを起動すればOKです。例えばChoreonoid起動時に
CPUPROFILE=choreonoid.prof ./build/bin/choreonoid
などとします。
その場合でもprofilerライブラリをリンクしておく必要がありますが、これはChoreonoidのCMake設定でENABLE_GPERFTOOLS_PROFILERをONにすることで実現できます。
実行が完了したら、以下のようにして結果のファイルを読み込みます。
google-pprof build/bin/choreonoid choreonoid.prof
ここでcallgrindと入力するとGUIのビュアーが表示されます。
あとはコンパイルオプションとして“-g3”とか“-ggdb3” でデバッグシンボルを埋めておいたり、“-fno-inline” でインライン展開を抑制したりしておくと、結果も分かりやすくなるかもしれません。これらはCMakeで該当する変数を設定することで実現できます。
情報ありがとうございます.
WRSが済んだら試してみます.
@nakaoka 様,
プロファイリングをやってみました.できましたが,結果をどう解釈していいのかがわかりません.
BodyROSに手を加えて2byte符号なし整数の深度画像をimage_transport経由でパブリッシュするようにしたプラグインを使っています(WRSで実際に使っていたコードです).ロボットのモデルはDoubleArmV7AにCOLOR_DEPTHのカメラを追加したもの,環境はWRS2020のTS-1です.
以下の3条件でデータを取りました.
- Choreonoidのみ
- 別の端末で
rostopic hz /DoubleArmV7/FRAME_FRONT_DEPTH_CAMERA/depth
- 別の端末で
rostopic hz /DoubleArmV7/FRAME_FRONT_DEPTH_CAMERA/depth/compressedDept
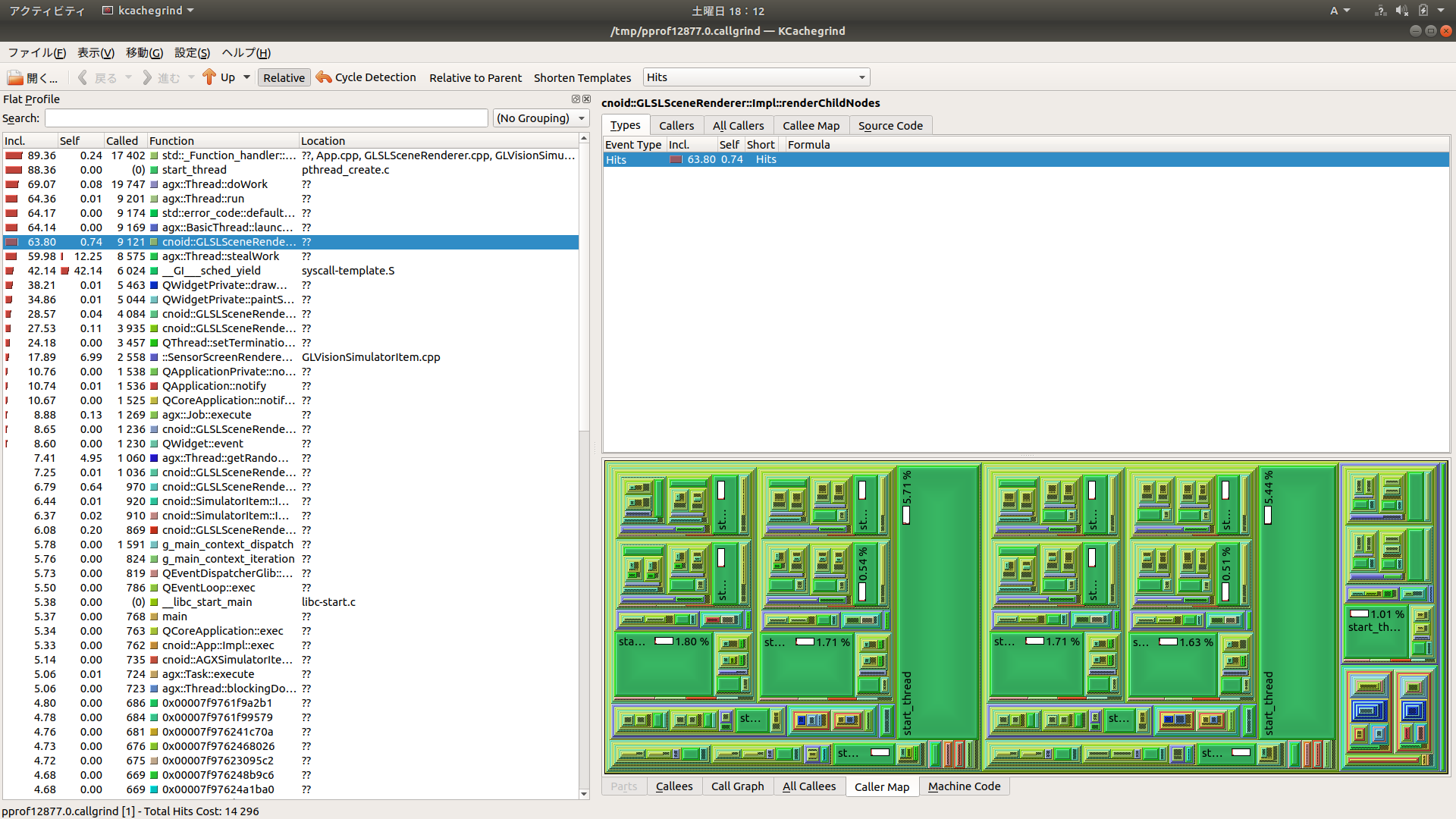
1の場合のプロファイラスクリーンショット
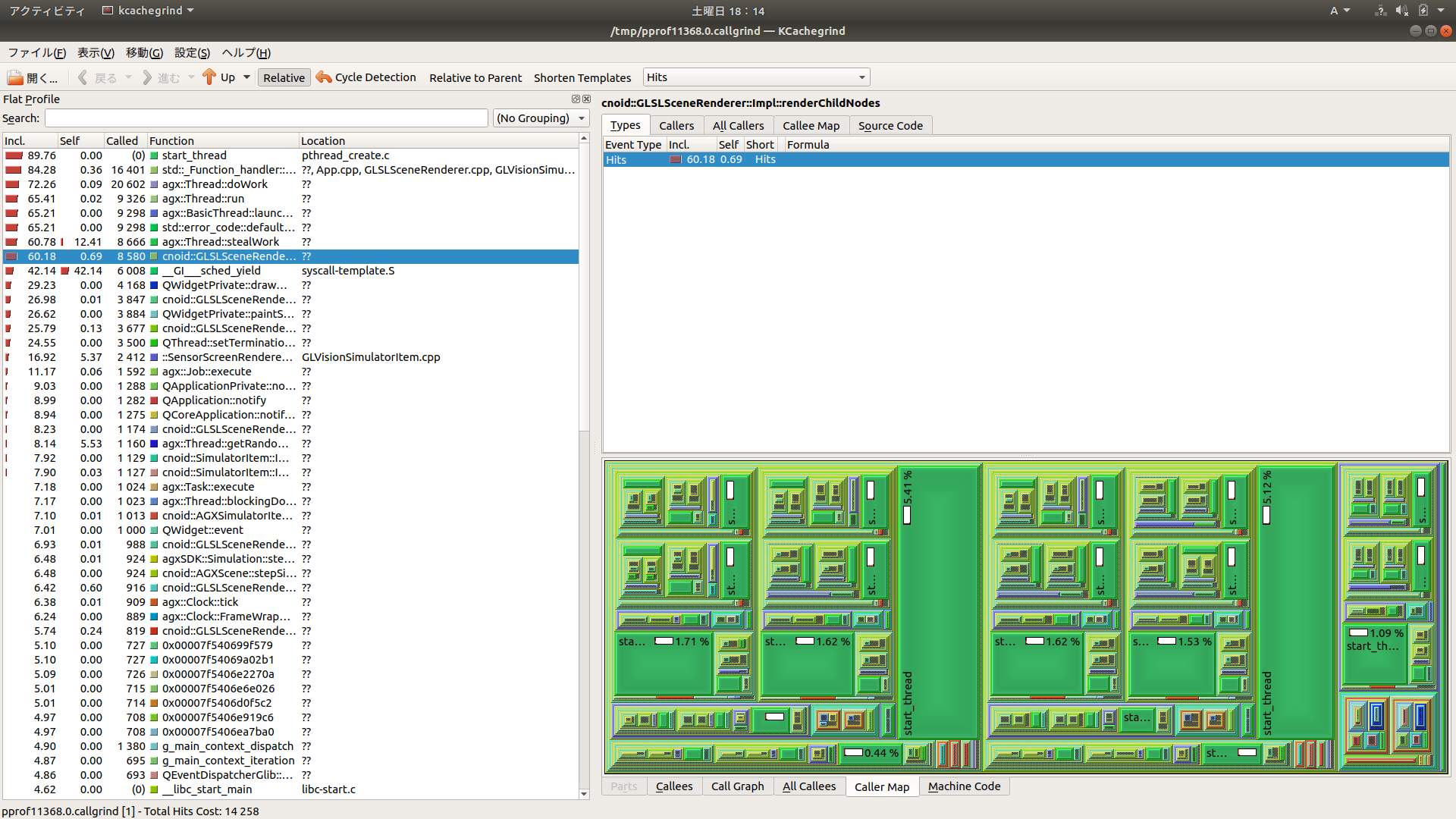
2の場合のプロファイラスクリーンショット
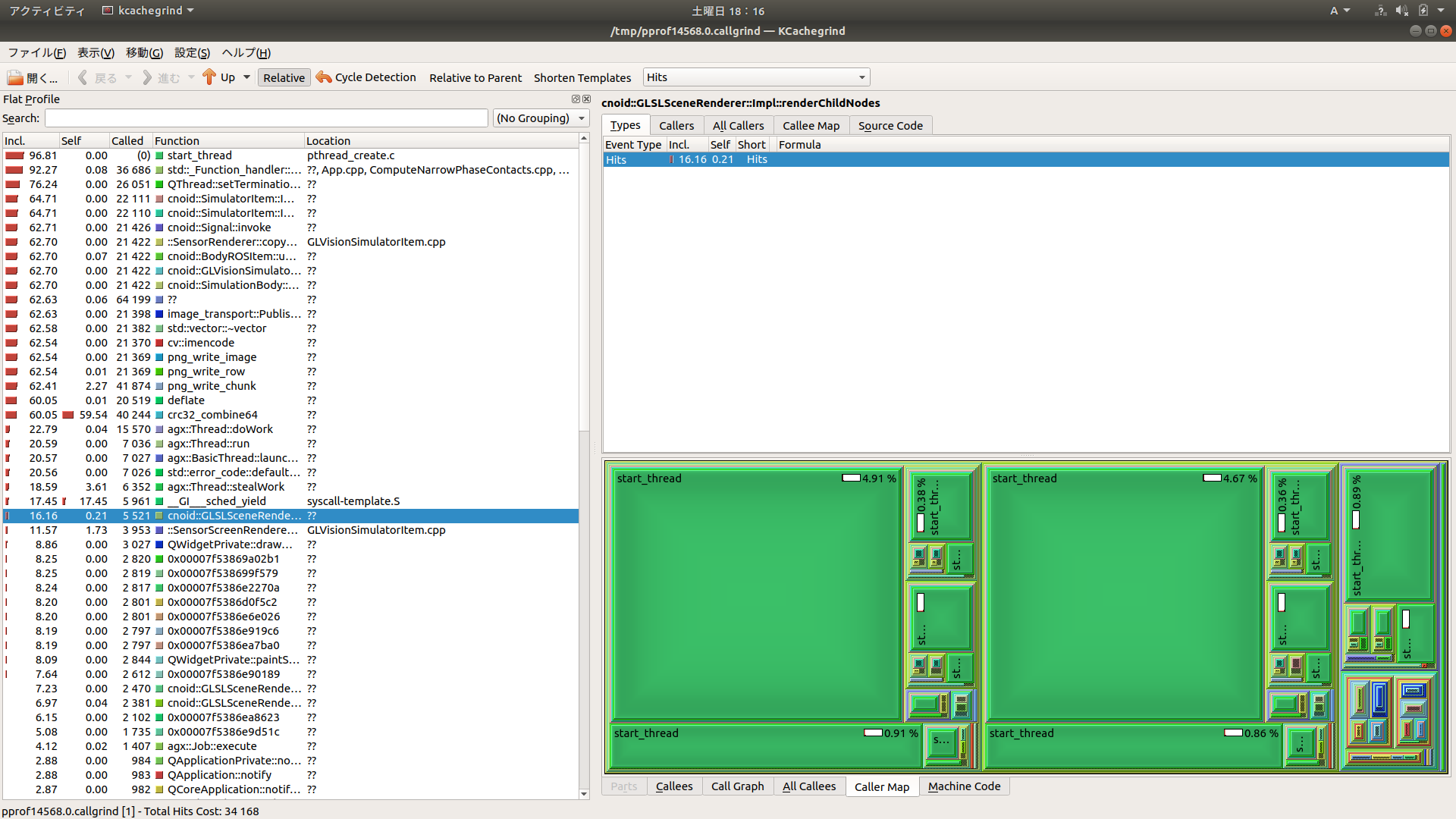
3の場合のプロファイラスクリーンショット
2の場合
- 計算時間 / シミュレーション時間 1.0
- rostopic hz 30
3の場合
- 計算時間 / シミュレーション時間 3.7
- rostopic hz 8
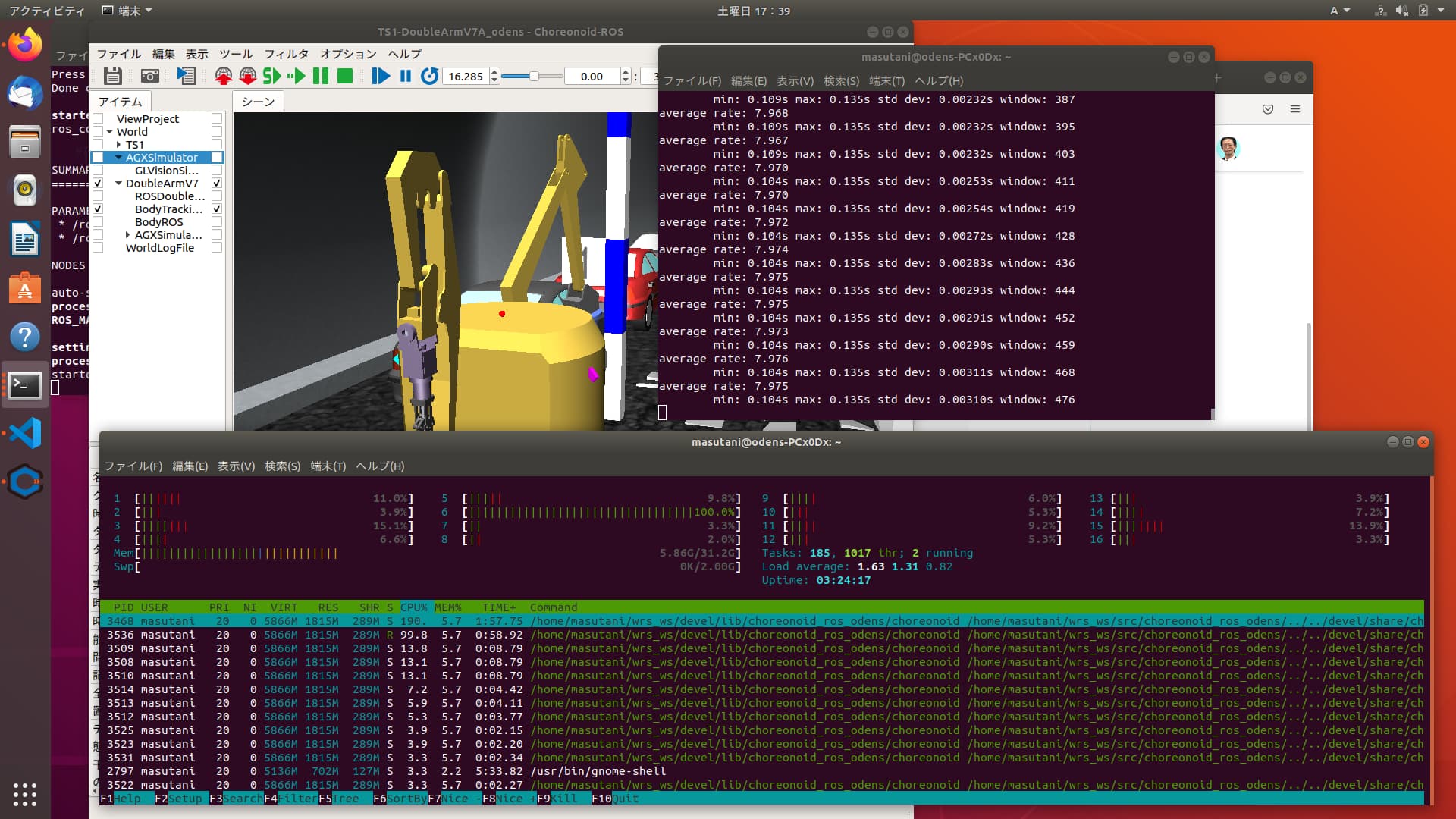
3の場合は,1コアの使用率だけが100%になる現象が起こっています.htopのスクリーンショットを添付します.
nakaoka
5
調査結果をお知らせいただきありがとうございます、確認が遅くなりましてすみません。
WRSの際にお話を聞きながら推測したところでは、BodyROSItemでセンサデータをpublishする際に、そのcontrol関数内での処理時間がかかっているのではないかということでした。その場合、処理が完了するまでシミュレーションのタイムステップの進行がブロックされるので、そこがボトルネックになって、シミュレーション速度も遅くなってしまっているのではないかと。
添付していただいたプロファイル結果の画像をみた感じでは、どうもケース3の場合にこの状況になっているように見受けられます。ケース3ではBodyROSItemの処理で62.7%の時間を消費していますね。一方で、物理計算を処理しているAGXの処理は20%程度のようですので、単にデータを送信するだけで物理計算の3倍ほど時間がかかっているということで、やはり送信の処理に問題があるようです。なおSimulatorItemやGLVisionSimulatorItemの処理もBodyROSItemと同様の時間がかかっていますが、これは上記のようにBodyROSItemで処理がブロックされることでそれにひきずられてこのようになっているのだと思います。逆に言えば、メインのシミュレーションループやセンサデータのシミュレーション(生成)処理については、そのほとんどがBodyROSItem側でブロックされていることによるもので、シミュレーション本体の処理は本来ずっと軽いのではないかと思われます。
1と2では画面中にBodyROSItemの割合が表示されていませんね。1は実際には通信が生じておらず、BodyROSItemの処理時間はほとんどかかっていないのでしょうね。少し意外なのは、2については送信をしているはずですが、1と同様にほとんど処理時間がかかっていないようです。本来は送信自体もそれほど重いものではなくて、それが3になって圧縮処理が入ることで異様に重くなっているのではないかと思われます。
というわけでこの結果についてはWRSの際に議論して推測したことがほぼあてはまっていたのではないかと思います。ただ具体的にボトルネックとなっていたのはどうも圧縮処理にあるようですね。いくら圧縮するとは言えこれだけの時間がかかるのは不自然ですね。よく分かりませんが、内部的に何が無駄な処理が入ってしまっているのではないかと思います。
3のプロファイル結果において、BodyROSItem以下にある、image_transportやcv::imencode、およびpng関係の関数、crc32_combine64の関数、このあたりで処理時間がかかっているようですね。実際にはどうも最後のcrc32_combine64関数でほとんどの処理時間がかかっているようですね。恐らくプロファイラ結果の"Self"という項目が、実際にその関数内で(他の関数の呼び出し時間は除いて)かかっている時間なのではないかと思います。これが正しければ、crc32_combine64に対してその割合が59.54%ということで、圧倒的にここで時間がかかっていますね。これがシミュレーションが遅くなっている一番根本の部分のようですね。
とりあえず上げていただいたプロファイル結果から分かるところは以上になるかと思います。あとは圧縮をする際のimage_transport以下の処理(関数)を追っていって、その処理時間を改善できないか調査することになるかと思います。
あとはBodyROSItemを改良して、control関数からさらにスレッドを生成してそこから実際の圧縮や送信の処理を行うことで、シミュレーション速度を改善できるかと思います。この改良は今後進めて行きたく思っています。
しかしながら、今回のケースでは圧縮にかかっている時間が物理計算の3倍程度と圧倒的なので、ここを改善しない限り、上記の改良をしても限界があるかと思います。
nakaoka
6
この件に関するご報告です。
あとはBodyROSItemを改良して、control関数からさらにスレッドを生成してそこから実際の圧縮や送信の処理を行うことで、シミュレーション速度を改善できるかと思います。この改良は今後進めて行きたく思っています。
この件について、ROS 2版になりますが、対応しました。以下のコミットになります。
上記書き込みから3年も経ってしまい、対応が遅くなりまして申し訳ありません。
この改良では、BodyROS2Itemごと(各ロボットごと)にセンサデータPublish用のThreadPoolを作成し、センサデータの更新があるとThreadPoolを介してPublishをするようにしました。この改良により、サイズの大きい画像データ等で通信量が多くなる場合でも、control関数をブロックせずにPublishできるようになり、シミュレーション速度の低下を抑えられるかと思います。
なお、Publish用のスレッドは各センサごとに用意したほうがよいかもしれませんが、とりあえずThreadPoolを使うのが実装しやすかったため、このようにしてあります。今後そのあたりは改良するかもしれません。
また、以下のRealtimePublisherというクラスがあり、こちらもスレッドを用いてPublishするというもののようです。
こちらも使えないか検討したのですが、現状ではrosdepやaptでインストールできるパッケージにはなっていないようだったのと、publishするためのAPIが通常のpublisherとはだいぶ異なるようだったので、今回は利用を見送ることとしました。